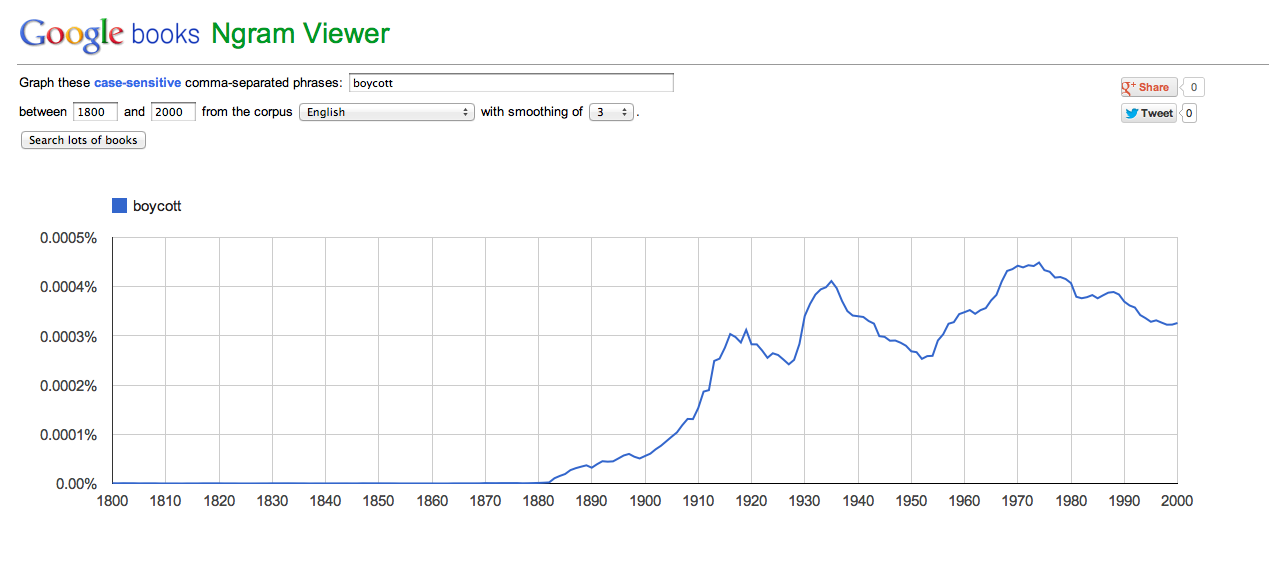
Roy Rosenzweig’s essay, Scarcity or Abundance? Preserving the Past in a Digit sheds light on how history on the Internet may not always be there. There are countless ways for information to get lost or deleted on the web. People tend to believe that what is put on the Internet will be there forever. Rosenzweig says, “Government archives similarly continue to rely on the unwarranted assumption that records can be appraised and accessioned many years after their creation.” This statement shows that even the highest offices i.e. Library of Congress are carelessly archiving important information on the web. Although they are most likely using the LOCKSS (lots of copies keeps stuff safe) principle, there is still no guarantee to documentation on the Internet.
I myself am guilty of using Facebook to archive many aspects of my life. Sometimes I resort to storing photos on Facebook instead of storing photos in a more secure manner such as a folder or putting the content in a flash drive. Say if Zuckerberg breaks down and deletes Facebook, what am I left with?
On the contrary, the April 16 Archive does good on the Internet by collecting and preserving memories of the Virginia Tech tragedy. Since memories fade, this archive is able to keep the authenticity of the tragedy alive. The stories of victims and family members provided on the site really help people carry on the slogan that came with the tragedy, “NeVer ForgeT.”
I think the best way to preserve history is to have hard copies of everything. To many these days it seems very old fashioned but it is the only feasibly logical mean of preservation. Pictures and family documents need to be printed and copies of everything should be put into hard drives. It’s important to recognize that if these things aren’t done, one shouldn’t be surprised if they lose everything.